

One of the big stories of the Covid-19 pandemic so far is the dramatic acceleration of digital transformation in the enterprise. According researchers at McKinsey, we are witnessing a historic moment, with decades worth of digital adoption taking place in a matter of weeks.
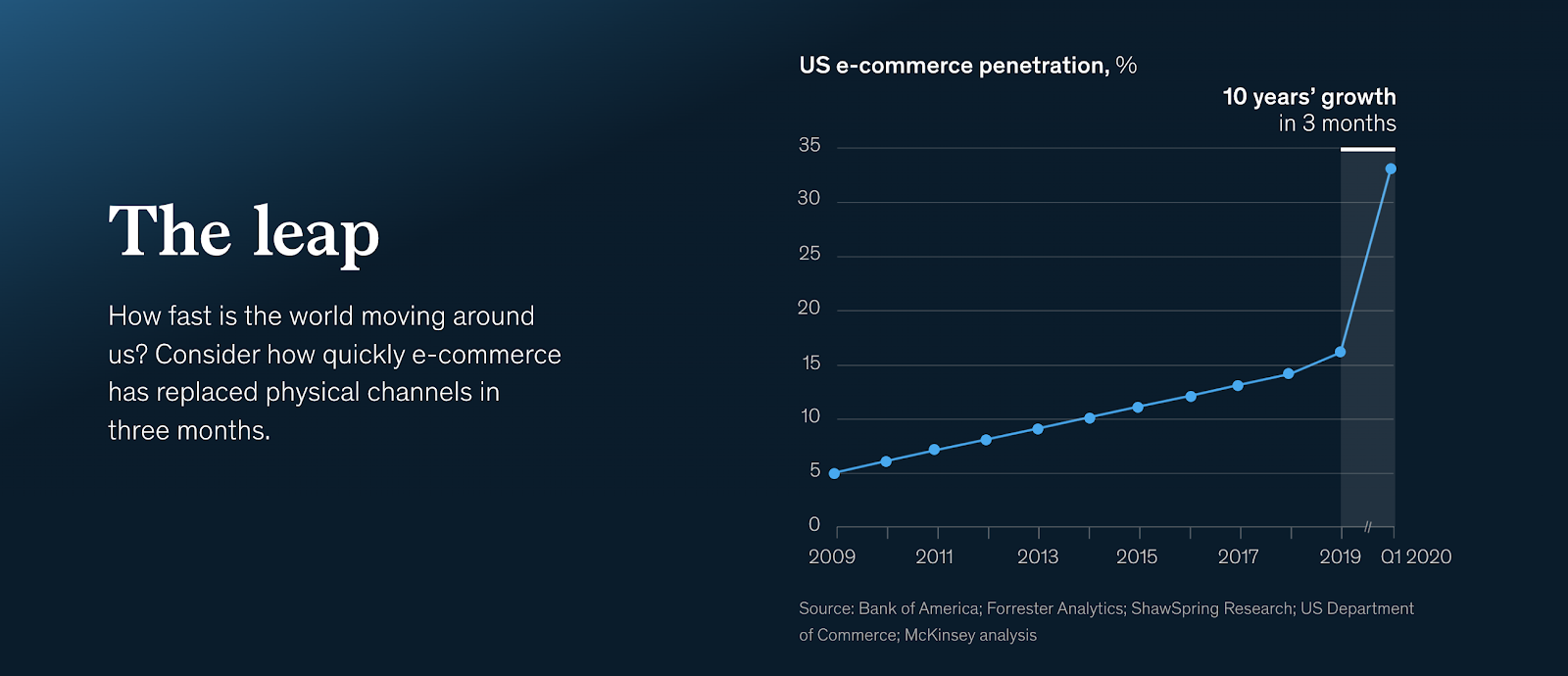 McKinsey Quarterly, Five-Fifty: The Quickening (July 2020)
McKinsey Quarterly, Five-Fifty: The Quickening (July 2020)
That’s great news for the data analytics industry. With Covid-19 resetting expectations for analytics overnight, it’s now painfully obvious that conventional approaches that were conceived in the 1980s don’t cut it anymore. Built by specialists whose passion for technology can overshadow the interests of the broader organization at times, the vast majority of analytics tech stacks in production today are fragmented, “best of breed” systems that are so large, complex and all-around unwieldy that it’s surprising when useful insights actually come out on time.
 A classic Rube Goldberg machine. When I look at traditional analytics technology stacks, this is essentially what I see (albeit way more expensive and way less entertaining to watch).
A classic Rube Goldberg machine. When I look at traditional analytics technology stacks, this is essentially what I see (albeit way more expensive and way less entertaining to watch).
According to Ray Wang, founder, CEO and principal analyst at Consellation Research, “Analytics used to be a retrospective activity where management teams met to discuss the past. We are now required to predict the future in real-time; waiting even an hour is too long.”
At the highest level, achieving speed and agility in data analytics is all about how you process and move data from the source to a consumable, analytics-ready format. Here are five must-haves for a data analytics stack to have any chance of keeping up:
#1) Easy, no-ETL data ingest
Companies rely on a growing number of applications to run their business – from core ERP and CRM systems to various department-specific tools. Every one of these is generating tremendously valuable data..
But you can’t analyze data right inside the source system. You need to move it first, and then put it into a more consumable, analytics-ready format. The process of extracting, transforming and loading data (ETL) typically requires a developer, especially when the data needs to move through a fragmented analytics stack. This is complex, time-consuming and highly prone to error.
This “ETL developer-in-the-middle” approach doesn’t work in today’s world, because the data sources you have today are not necessarily the ones you will have tomorrow. Having ETL developers on hand to translate and ferry data to and from this growing constellation of data sources is not even remotely practical.
If ETL developers can’t scale to meet demand, you essentially end up forfeiting tons of data. What you need instead is a system that makes ETL developers 100x more productive by making the ETL process 100x more efficient. When you do that, your valuable ETL developers are no longer mired in grunt work and can focus on far more valuable activities, such as building a business-friendly semantic layer–an area where they can really shine..
#2) A business-friendly semantic layer
After decades of reliance on “data experts,” business users are taking their place on center stage as the most important people to empower with data.
So what if they aren’t up to speed on the latest in cloud data lake architecture? They bring something infinitely more valuable to the table – extensive and intimate knowledge of your business and the markets. Who else has a better read on which data sets, dashboards and reports are actually useful? Nobody.
Without a business-friendly semantic layer to map complex data into familiar business terms–product, customer, revenue, etc.–business users often lack the confidence to use a data platform to its full extent. The risk of breaking something or making a mistake is too high. Imagine, for example, that you are creating a report for the executive team outlining transaction volumes over the past quarter.
Chances are you don’t realize that most business applications typically don’t delete transactions, but “end-date” them instead for auditing and archival purposes. Now, imagine that this logic is not captured in the semantic layer and the numbers you present to the exec team are off by 20 percent because you didn’t account for duplicates. Your confidence is going to take a huge hit, which will dissuade you from using analytics in the future. That’s bad for you and the business.
#3) Open, standards-based components
In the software development world, there is a broad, long-term trend toward openness and interoperability. This same is true in enterprise analytics today. Adhering to open standards not only protects against vendor lock in – it also keeps the door open to innovation, no matter where it comes from.
For instance, let’s say an earth-shattering new data processing tool comes out tomorrow. I can pretty much guarantee that it will support Parquet, the de facto standard file format today. Why? Because trying to launch a new product with a proprietary file format these days is like trying to push an asteroid up a mountain. If you are using a data platform that adheres to open standards, trying out this new tool is no problem at all – the data is in a format that plays nicely across all of your tools.
Here’s a rule of thumb: Platforms that are built with open standards come out on top because they have to win their customers’ business every day. Instead of locking you into a proprietary platform, they focus on delivering the best possible user experience. The incentives for the platform’s creators and users are aligned, and everyone is better for it in the end.
#4) Integrated data science tooling
The notion of machine learning and data science tools being separated from business analytics is totally insane, and yet that’s how most traditional analytics tech stacks are set up. But data science tools aren’t just for data science – they are fast becoming the tools of choice for data enrichment as well.
Data science and data analytics are two sides of the same coin. The latter is trying to build reports and dashboards showing what recently happened in the business – e.g. revenue over the past three months. The former is trying to predict the future – e.g. revenue over the next three months. They are different views of the exact same data.
Bringing these two functions together on the same platform has immense benefits. First, it eliminates waste stemming from duplicate data preparation. Moving data from source systems and prepping it for data science is grueling, time consuming, error prone work, and it is essentially the same process as data prep for analytics.
But that’s not all. Keeping these two functions separate also prevents each side from helping the other. For instance, business users looking at analytical dashboards typically only see historical data. Insights from predictive analytics? Nowhere to be found on the dashboard. Yet it’s extremely valuable to expose business users to predictive data. When data science insights are combined with data analytics insights, business users are no longer constrained to looking at the past – they can also think more strategically about the future, which is exactly what you need to compete in today’s business environment.
#5) Secure and governed data, access, and computational resources
You can’t be an analytical organization without giving people access to data. You also have a responsibility to protect the data of users and the organization itself.
With traditional approaches to data analytics, these two demands are at odds. When your data workflow is fragmented across seven or eight different products, it leads to rampant data copying, because you can’t do anything productive with the data otherwise. People at every stage of the journey are forced to make separate copies of the data, transforming it in different ways before passing it to the next stage.
This setup not only opens you up to cybercrime and legal risk but also invites internal questions about the accuracy of data. If you are an executive who needs a particular set of data to make a decision and everyone around you is circulating similar, but slightly different versions of the data, which data set do you trust? If you are struggling to get people at your organization to use data, it might just be because they don’t have much confidence in it.

If you can’t seem to get what you want, need or expect out of data analytics, it might just be time to take a serious look under the hood. Trying to match the speed and agility of trailblazers with a system built on the technology designed in the 1980s is just asking for frustration and regret. You can’t outfly a jet fighter with a hang glider.
That’s especially true today, as the Covid-19 pandemic resets demands and expectations for business analytics. Endlessly debating arcane technical distinctions is a surefire way to get left behind. Today, driving real, tangible business outcomes and ROI with data is what it’s all about.