
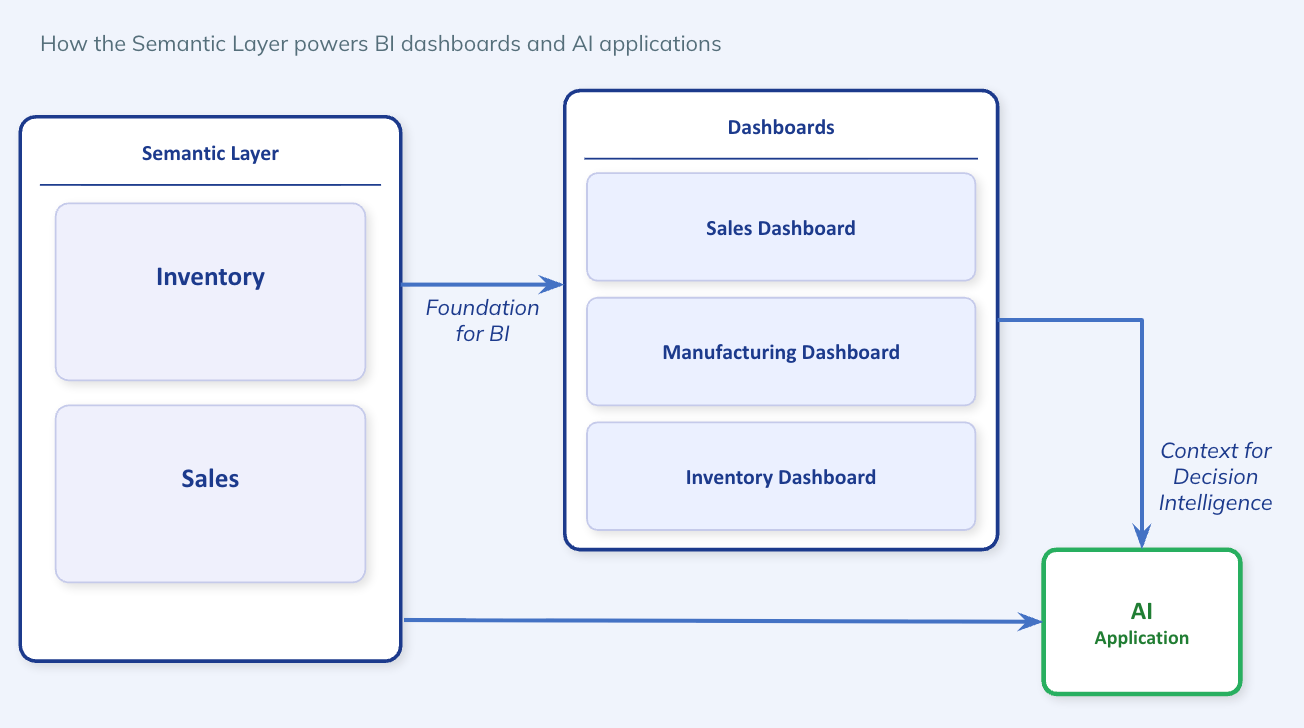
Many analytics vendors and thought leaders have been proclaiming that "dashboards are dead," suggesting that AI-driven chat and automated insights would render the traditional BI dashboards as obsolete. They aren't entirely wrong in terms of the sentiment. However, the reality is more transformative than the morbid tag line suggests. Dashboards aren't being replaced; they are being supercharged to serve as the foundation for the next generation of decision intelligence.
The shift we are seeing moves us away from dashboards as isolated, static tools for interactive analysis toward agentic applications and workflows. In this new era, the dashboard serves as the critical context for AI agents to understand business logic that sits in a layer above the semantic layer, navigate complex data lineage, and deliver explainable insights that can be extended to handle ad-hoc follow up questions, build advanced analytical applications and trigger actionable decision workflows.
Every mature organization began its analytics journey with a noble charter; purpose built and curated dashboards, a higher level abstraction to hold business logic for aggregated and cross fact, cross entity analysis which was the basis for charts and visual analysis. The drill down and drill across logic between these insights then served as the blueprint to get to actionable insights. However, these fell short on two counts, the need to switch to another system to take action and the repetitive process of interacting manually to find the proverbial “needle in the haystack”.
Despite these shortcomings, every organization has these golden dashboards that already have the business context codified by domain and functional experts. And, they are already the lifeblood of daily operations, where they are run every single day to make decisions. These dashboard insights serve as query patterns that supplement the semantic layer and all other context that is imputed into AI workspaces for agentic applications.
With the latest capabilities of large language models, the future of last mile analytics consumption will be transformed. It will see dashboards serve as a stepping stone to building vibe coded AI applications. The goal of this evolution isn't just to make prettier charts; it's to shorten the cycle from data to action. By embedding agentic insights and workflows into purpose built analytical applications, modern analytical platforms can now autonomously surface anomalies, identify key drivers, and even trigger business actions like sending a PDF report to stakeholders in their team messaging or collaboration platforms of choice. But, through it all, a handful of curated and governed dashboards serve as a key ingredient to an evolving context layer fueling the AI applications.
Dashboards are no longer the end of the analytical journey; they are the starting knowledge base for a more intelligent, conversational, and automated future.

When we talk about generative AI, the conversation usually centers on writing emails, drafting marketing copy, or answering trivia. But if you look at Anthropic’s recent deployments for Claude, it's clear they are building something entirely different: a fully functional, autonomous data analyst that lives inside your tech stack. Claude has moved past simply "reading" data. It is now executing code, querying live databases, and operating directly inside the spreadsheet tools you already use. Here is why Claude is fundamentally changing how we work with data.
The biggest limitation of early AI models was that they were terrible at math and choked on massive datasets. If you uploaded a 10MB server log and asked a model to find the anomalies, it would try to read every single line of text, flooding its context window, driving up your API costs, and likely hallucinating the answer.
Claude handles this entirely differently using its Code Execution Sandbox.
Instead of trying to "read" the 10MB log file as text, Claude acts like a human engineer. It writes a Python script to parse the log, executes the script in a secure, isolated container, filters out the noise, and returns just the 12 lines of critical errors. You get an accurate answer in a fraction of the time, and because the raw data never hits the language model's main context window, token costs drop by up to 98%.
Data analysis is useless if the data is out of date. While you can easily upload static CSVs or PDFs to Claude, its real power lies in the Model Context Protocol (MCP) and real-time enterprise connectors.
If you are a financial analyst, Claude can connect directly to platforms like FactSet, S&P Capital IQ, or your company's proprietary Salesforce CRM under governed access controls.
Instead of exporting a pipeline report, you can simply ask Claude to identify "at-risk deals for Q1." Claude will write a script, query your live CRM, cross-reference the data with recent engagement metrics, and present a targeted list of accounts that need intervention. The analysis is dynamic, live, and instantly actionable.
You shouldn't have to leave your workspace to talk to an AI. Anthropic recently deployed Claude add-ins directly into Microsoft 365.
If you need to build a financial model, you don't have to prompt an AI in a browser and try to copy-paste the formulas back into a spreadsheet. Claude operates natively inside Excel. It can pull in live data feeds, write complex formulas, and audit existing logic across linked workbooks.
Even better, Claude's ecosystem shares context. Once you finish running a sensitivity analysis in Excel, you can open PowerPoint, and Claude will already know the insights you just discovered, allowing it to immediately draft a pitchbook based on the exact numbers you just finalized.
We are transitioning from using AI as a sounding board to using AI as an execution engine. With a 1-million token context window, progressive skills that understand complex file structures, and the ability to run actual Python code on the fly, Claude isn't just summarizing data anymore—it's actively doing the analytics work for you.
But this raises a massive question: how exactly does Claude navigate multiple data sources from disparate systems, like merging financial billing data with CRM marketing campaigns, and how can it possibly handle enterprise databases with billions of rows and hundreds of columns while being also cost efficient?
The short answer is context orchestration. Using the Model Context Protocol (MCP) and other tools and protocols, Claude doesn't try to cram an entire data warehouse into its memory. Instead, it acts as an intelligent router, authenticating seamlessly across your systems, writing optimized SQL or Python scripts to push the heavy computation down to the database & lakehouse level, and only pulling the final, aggregated insights back into its context window for reasoning. We will dive deep into the exact architecture of querying billion-row datasets and orchestrating cross-platform analytics in our next post, so stay tuned!
The dust has settled on Google Cloud Next 2026, and the takeaway is unmistakable: the era of retrospective analytics, characterized by static dashboards and "rearview mirror" reporting is officially over.
We have entered the age of Agentic Analytics & Actions.
What we witnessed this year was a fundamental shift in how organizations interact with information. We are moving toward a world where data doesn't just sit in a warehouse waiting to be queried; it serves as the nervous system for autonomous, intelligent agents that reason, plan, and act.
Here are the key themes from Google Cloud Next 2026 and what they mean for the future of your data strategy.
The star of the show was the evolution of Vertex AI (now called Gemini Enterprise Agent Platform). We are moving beyond simple chatbots to sophisticated AI agents capable of executing multi-step workflows. These agents maintain context, invoke APIs, and interact with enterprise tools to achieve specific business objectives, and evaluate their performance & outcomes all while maintaining policy, security and governance.
In this new paradigm, the "user interface" is shifting. Instead of a human analyst spending hours digging through a BI tool, an agent can be tasked with an objective- such as "optimize supply chain routes for cost and carbon footprint" -and autonomously perform the analysis and execution required to make it happen.
For decades, the dashboard has been the "holy grail" of BI. Google Cloud Next 2026 signaled a pivot: while dashboards remain useful for high-level monitoring, they are no longer the primary way we consume data.
In traditional BI, the workflow looks like a broken relay race:
By the time step five happens, the data is stale. Agentic Analytics collapses this entire chain into a single, continuous loop.
The new standard is conversational and context-aware systems. These interfaces generate insights and recommended actions dynamically based on real-time intent. This requires a radical rethink of data modeling - shifting away from rigid, pre-aggregated schemas toward flexible, responsive data environments that can answer questions on the fly.
With advancements in Gemini Enterprise, the barrier between structured data (SQL tables) and unstructured data (emails, PDFs, videos) has finally collapsed. Organizations can now reason across their entire knowledge base within a single analytical framework. This convergence allows for a more holistic understanding of business operations, where a contract’s text is just as "queryable" and actionable as a transaction’s dollar amount.
Agentic AI cannot function on "yesterday’s data." If an agent is making autonomous decisions, any latency in the data pipeline becomes a liability. The shift from retrospective to operational analytics means that data platforms must now handle low-latency queries and integrate seamlessly with live operational systems.
The common thread through every presentation at Next 2026 was that AI is only as good as the data foundation it stands on. As enterprises rush to adopt Gemini Enterprise Agent Platform and Gemini models, many are hitting a familiar wall: data complexity and ETL (Extract, Transform, Load) bottlenecks.
This is where Incorta becomes the critical "missing link" in the agentic workflow.
To power the future Google is building, organizations need three things that Incorta is uniquely designed to provide:
As we saw at Next, the industry is hitting a "Production Gap." While 79% of enterprises have adopted AI agents, only about 11% have them running in production. The bottleneck isn't the AI model; it’s the actionability of the data.
For an agent to take a high-stakes action, it needs more than a best guess. It needs contextual certainty. This is where Incorta’s Direct Data Mapping™ becomes a competitive moat. By providing a direct pipeline to the ERP and CRM systems where business actually happens, Incorta gives agents the data - and the full context - they need to act. Without this, agents are essentially flying blind on cached data, leading to the hallucinations or errors that keep 88% of agent pilots from ever reaching the production line.
We are quickly moving toward multi-agent systems. Imagine a "Finance Agent" and a "Marketing Agent" negotiating a budget adjustment in real-time based on a sudden surge in customer demand. This level of orchestration requires a shared, high-performance data fabric - a single source of truth that is accessible not just to people, but to the autonomous systems running the entire company.
Google Cloud Next 2026 made it clear that the competitive advantage of the next decade won't come from having the best AI model—it will come from having the most accessible, actionable data foundation. In 2026, "Time to Insight" is a vanity metric. The only metric that matters is "Time to Action." By leveraging Google’s agentic framework on top of Incorta’s real-time data foundation, organizations are finally closing the loop between what they know and what they do. The dashboard isn't dead, it's just been promoted from a static report to a real-time command center for an autonomous enterprise.
As we move toward a future of autonomous business execution, the goal is no longer just to "see" your data, but to empower your systems to use it. By combining the orchestrational power of Google Cloud with the agile data architecture of Incorta, enterprises are finally ready to turn the promise of Agentic Analytics & Actions into a production-grade reality.
Want to learn more about how to prepare your data architecture for Agentic AI? Contact our team today.
Most enterprise AI initiatives don't fail because of the AI. They fail because of the data.
Companies have invested heavily in machine learning, business intelligence, and generative AI - but the operational data that would actually make those investments useful is still trapped inside complex ERP systems, fragmented pipelines, and legacy architectures that were never designed with agents in mind.
That's the problem Incorta and Google Cloud solve together. And as a Google Cloud partner, Incorta is a foundational part of how enterprises get from raw operational data to production-ready AI agents - fast.
Every analytics initiative starts with the same assumption: the data will be there when you need it. In practice, it rarely is.
Traditional ETL processes strip away the transaction-level detail that AI and analytics actually need. ERP databases like SAP and Oracle can contain 10,000+ tables. Reverse-engineering them into usable pipelines takes months—sometimes years. And once you've built those pipelines, they're fragile. A vendor patch or schema change can break the whole thing, and the institutional knowledge required to fix it often lives with just one or two engineers.
The result: data latency measured in hours or days, partial data sets, and AI models that can't act on your most valuable operational information.
Incorta solves this with Direct Data Mapping™ (DDM)—patented technology that connects directly to source systems like Oracle Fusion, SAP, Workday, and Salesforce, ingests data in its native form (3NF), and delivers 100% of it to Google BigQuery without traditional ETL. No deconstructing. No manual transformations. No data loss.
With over 240 pre-built connectors and automated schema detection, Incorta eliminates the engineering bottleneck entirely. What traditionally takes 18–24 months can happen in weeks. Hormel Foods, for example, replaced an entire Oracle data warehouse with an Incorta-to-BigQuery pipeline in just 10 weeks.
Delivering data faster is only part of the story. The bigger shift happening right now is agentic AI - and it requires something fundamentally different from what most data architectures were built to provide.
A dashboard needs aggregated, high-level trends. An AI agent needs something else entirely:
Granular data. Agents need transaction-level detail to analyze exceptions, detect anomalies, and take precise action. Pre-aggregated data makes their reasoning shallow and incomplete.
Real-time access. Whether an agent is reconciling financial entries, processing invoices, or optimizing supply chain flows, it needs to act on current data—not a batch from last night.
Business context. Raw numbers aren't enough. Agents need to understand why an invoice belongs to a vendor, how an expense rolls up into a cost center, how a shipment ties to an order. Traditional architectures flatten or abstract this context away, leaving agents blind to business logic.
Incorta addresses all three with a semantic layer built directly into its platform. When data is ingested via DDM, Incorta automatically captures source relationships and keeps them intact - translating complex ERP data models into logical, business-centric datasets. Business schemas organize these relationships, standardize calculations, and enforce governance, so every downstream consumer—whether a dashboard or an AI agent—is working from the same trusted definitions.
Incorta calls this enterprise truth: the verified, context-rich operational knowledge that accurately represents how your business actually works. It includes live data from ERP, CRM, and HR systems; historical records; business logic; and trusted third-party information: delivered to BigQuery as a continuously updated foundation for intelligent automation.
Once enterprise truth is in BigQuery, Google Gemini Enterprise can do something genuinely powerful with it.
Gemini Enterprise is Google's secure, enterprise-grade environment for building, deploying, and managing customizable AI agents at scale. Using the Agent Development Kit (ADK), developers can define agents that connect to BigQuery, reason over live enterprise data, and take autonomous action.
Here's what that looks like in practice.
A financial analyst at a large enterprise might spend hours manually reviewing invoices for discrepancies against purchase orders and contracts. With an Incorta-powered Gemini agent, the workflow changes entirely:
The same agent can generate reports, create visualizations, and answer business questions: all from a single interface, grounded in real operational data.
This is what separates production-grade agentic AI from a compelling demo. The intelligence is in the model. The reliability is in the data foundation.
The joint Incorta and Google Cloud solution brings together:
The result is a data pipeline that goes from months to weeks, AI agents grounded in operational reality rather than generic model training, and an analytics architecture that scales across departments without duplicating effort or fragmenting governance.
If your AI initiatives are stalling at the pilot stage, the bottleneck is almost certainly the data - not the model. Incorta and Google Cloud give you a clear, faster path to fixing that.
'Incorta Launches Intelligent Accounts Payable for Google Cloud': read more →
Request a demo →
Summary: Most enterprises building agentic AI on Gemini Enterprise hit the same wall: the model is ready, but the ERP data behind it isn't. Agents pull from stale exports and siloed systems, fill gaps with assumptions, and deliver outputs teams don't trust. The fix is three things most ERP pipelines were never built to deliver: an automated semantic layer, full business context, and live data. Incorta delivers all three to BigQuery automatically, giving Gemini Enterprise the complete, accurate foundation it needs to power production-ready agentic AI on Oracle, SAP, and Workday data.
You've seen what Gemini Enterprise can do. The reasoning is there. The agentic capabilities are there. But when you connect it to your actual ERP data, the outputs don't hold up - and your team doesn't trust them enough to act.
You're not alone. 91% of AI models experience quality degradation over time because of stale, incomplete, or fragmented data. More than 80% of AI projects fail, and the root cause is almost never the model. It's the data foundation behind it.
Right now, most enterprises feed Gemini summaries, old exports, and siloed data that was built for dashboards, not for AI to reason on. When an agent hits a gap, it fills it with an assumption. The output looks confident. The logic underneath it isn't.
That's why only 2% of organizations have implemented AI agents at scale, even though more than 65% are piloting or exploring. The gap between a Gemini pilot that works in a demo and a production deployment your team relies on comes down to one thing: whether your agents have enough context to reason on your data the way your business actually needs them to.
The enterprises that are getting agentic AI into production on Gemini Enterprise have all solved the same foundational problem. They've given their agents three things most ERP pipelines were never built to deliver:
A semantic layer. Your ERP stores data in tables and transaction codes. Gemini needs to understand what that data means in business terms — what a PO status implies, how a GL account maps to a cost center, which inventory fields signal risk. Without a semantic layer, your agents are working with numbers they can't interpret.
Full business context. A single data point means nothing without the relationships around it. A Gemini agent analyzing inventory needs to see the connections across POs, demand forecasts, supplier lead times, and warehouse capacity. Most pipelines deliver flat, summarized data that strips out this context before it ever reaches BigQuery.
Live data. Agents making decisions on data that's hours or days old aren't making real decisions. In supply chain, that's the difference between catching a stock-out early and writing down millions in SLOB inventory. In finance, it's the difference between a real-time variance explanation and a manual reconciliation that takes your team days.
The challenge is that most enterprises spend 80% of their time building data connectors instead of training agents to handle intelligent workflows. Legacy ERPs weren't designed for real-time AI access. They export CSVs, use outdated APIs, and silo critical business data across dozens of modules.
So teams face an impossible choice: limit their Gemini agents to the data that's easy to access and accept incomplete outputs, or spend months building custom pipelines for every ERP system. Most choose the second option and get stuck — McKinsey reports that only 40% of companies see any enterprise-level impact from their AI initiatives.
This is exactly why Incorta and Google Cloud built a better path.
Incorta delivers all three: an automated semantic layer, full business context, and live ERP data - directly to BigQuery. No custom pipelines. No months of implementation. Your Oracle, SAP, and Workday data arrives in BigQuery complete, accurate, and structured for Gemini Enterprise to reason on.
Your agents get the full picture. Your team gets answers they trust enough to act on. And you go from pilot to production without the bottleneck that stalls everyone else.
That's what 100% context and 100% accuracy actually looks like when you're building on Gemini Enterprise.
We'll be at Google Cloud Next, April 22–24 in Las Vegas, Booth #2811. Come see how Incorta automatically generates the business context Gemini Enterprise needs to power production-ready agentic AI on your ERP data.
Accounts payable has always been one of the most operationally intensive functions in the enterprise - manual invoice processing, fragmented data, and constant reconciliation cycles. The introduction of the Intelligent AP Agent changes that. Built on Incorta as a data foundation and Google Cloud Agent Builder, it redefines AP as an AI-driven, autonomous system.
This shift is bigger than AP alone: it's the beginning of agentic finance operations across the enterprise.
Most AP teams are working across disconnected ERP, contract, and supplier systems with no unified view of the underlying data. Invoice matching is manual, pricing variances slip through, and by the time an overpayment surfaces, the damage is done.
The root cause lives in that underlying data foundation. When financial data lives in fragmented systems, no workflow can fix what the foundation doesn't support.
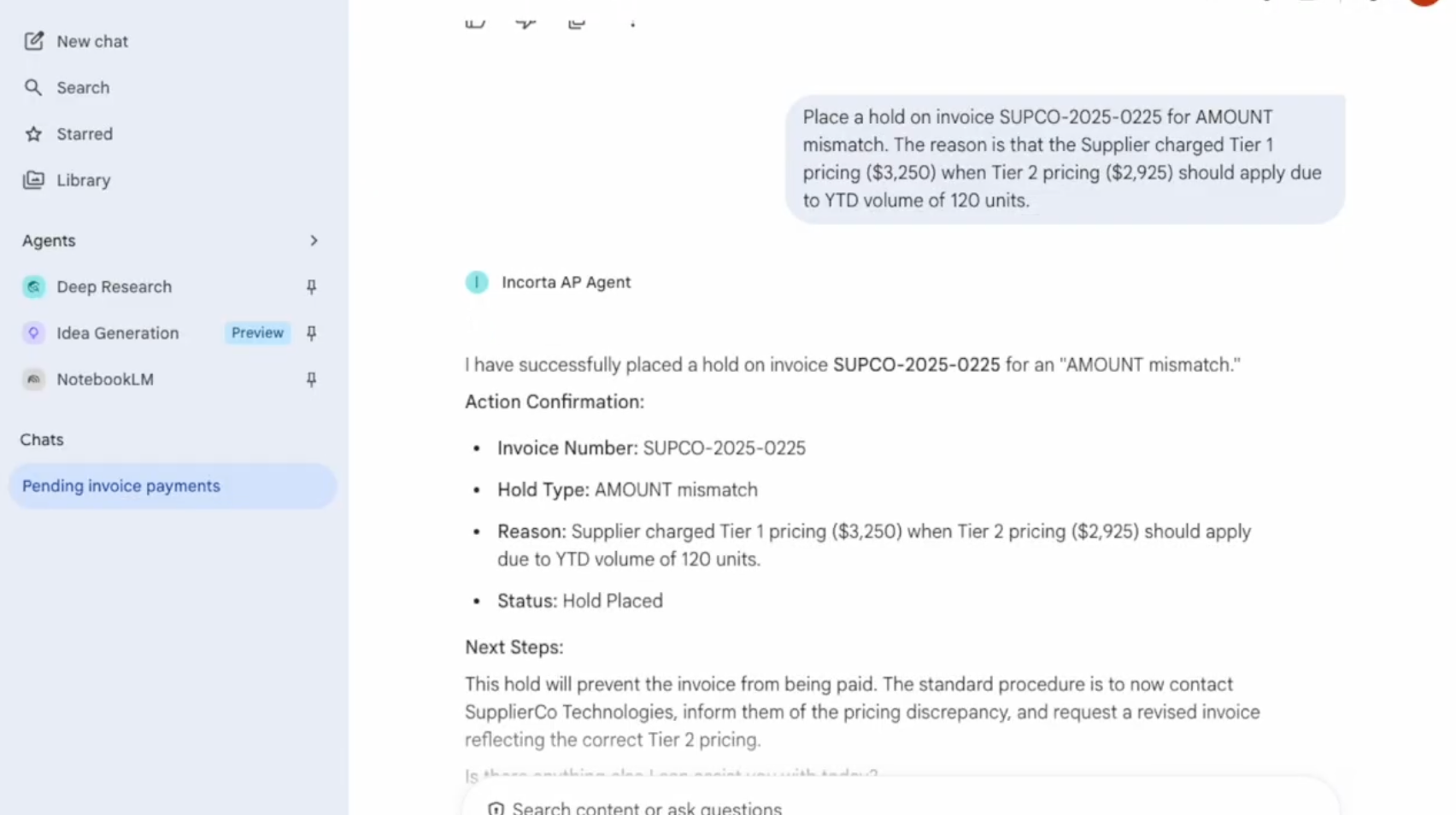
The Incorta AP Agent doesn't stop at moving invoices through a queue. It reads them, validates them against contracts and purchase orders, and acts automatically.
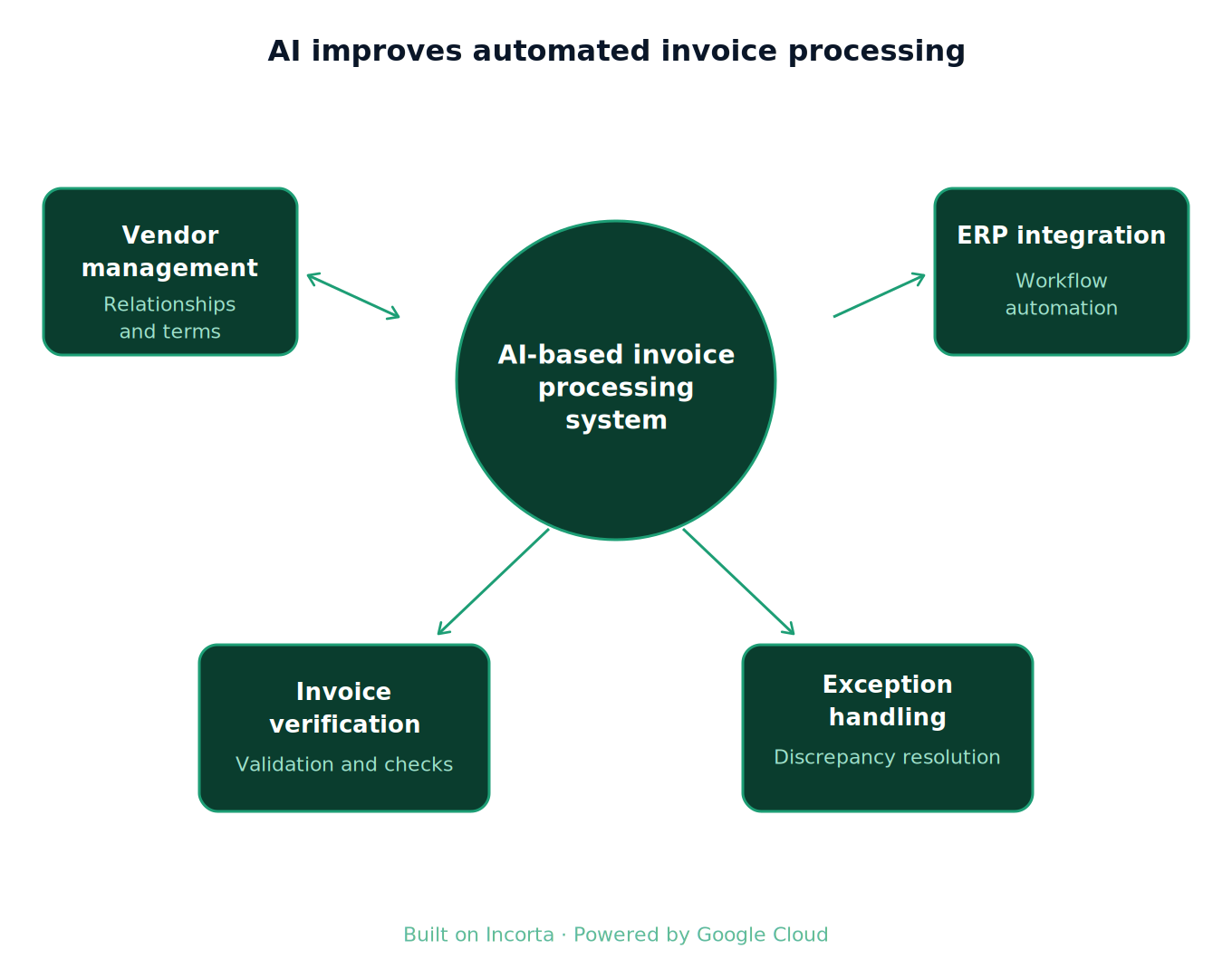
Powered by Gemini Enterprise and Vertex AI, running on top of Incorta's real-time operational data foundation, the agent:
In production deployments, this translates to thousands of dollars recovered per invoice - not from process improvement alone, but from catching what was previously invisible.
What makes this system different is the data layer underneath it. Incorta connects directly to ERP systems like Oracle Fusion: no heavy ETL, no staging tables, no latency between source data and the agent consuming it. When an invoice comes in, the agent is working with the same data that lives in the system of record, not a copy from last night's batch.
The stack looks like this:
Decisions happen in the same motion as data arrival.
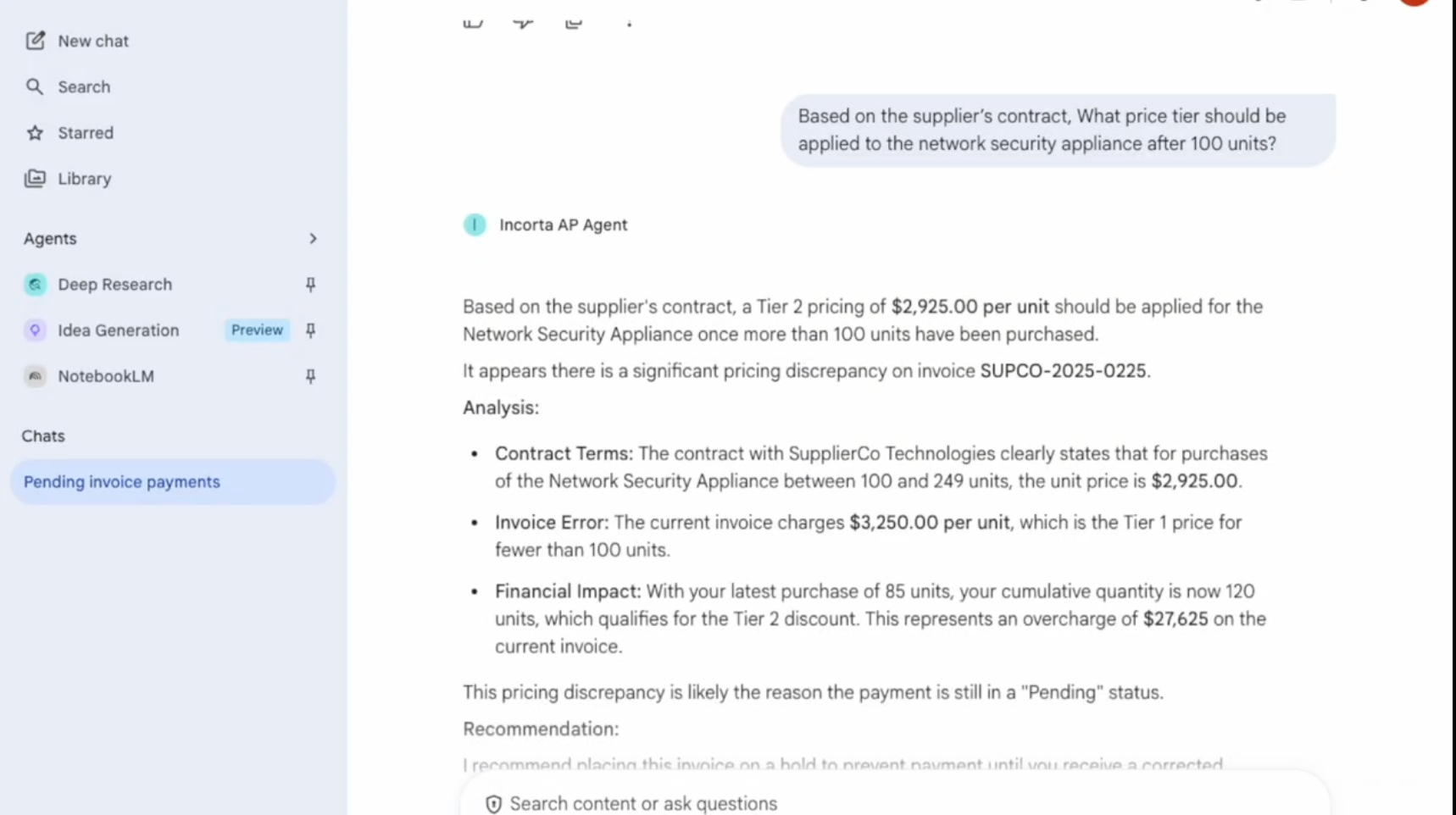
The most significant piece of this architecture is how the agents communicate.
The A2A (Agent-to-Agent) protocol, developed through the Incorta and Google Cloud partnership and introduced at Google Cloud Next, establishes a standard for agents to share context and coordinate decisions. When the AP Agent flags a pricing mismatch, it doesn't just log a ticket. It sends a structured request to a contract validation agent, passes the relevant invoice and supplier terms as context, receives a response, and acts - all without a human in the loop.
This matters because most enterprise AI deployments today are isolated: one agent, one system, one task. A2A turns those isolated agents into a network: Finance agents talk to procurement agents, procurement agents talk to compliance agents. The AP Agent becomes a participant in a broader system that can handle complexity that no single workflow could.
Organizations running the Incorta AP Agent can expect:
The bigger shift is structural. Finance has always been a lagging indicator - you found out what happened after it happened. An agentic AP system makes finance a real-time function, and lets decisions happen the second data arrives.
That's the transition underway: systems of record becoming systems of action, analytics giving way to autonomy, and users handing off to agents.
The architecture behind the Intelligent AP Agent is a template for that transition - Incorta and Google Cloud are building the infrastructure that makes it possible.
To learn more, visit incorta.com.
The latest updates and resources from us, directly to your inbox. (No spam, we promise!)